
I came across Kubernetes a few times while looking for a simple way to manage infrastructure and deployments for over 50 PHP applications. And every time, I came to the conclusion that it wasn't the right tool for the job. I won't go over the reasons in this article, but if you've looked into Kubernetes (for Laravel and other monolithic apps), you'll understand what I mean.
I also checked Docker Swarm and MRSK (MRSK in particular sparked my interest). However, I am not a fan of containerization for monolithic applications. Other than being able to control the runtime environment using code, I simply don't see the benefits.
So I started with a blank configuration file and worked out how I want to manage the infrastructure for all applications from a single point.
I divided the process into two tasks: managing the runtime environment (cluster servers) and managing the deployment process.
For the cluster definition, I had this:
php: [ 7.4, 8.2 ]
request_duration: 30
request_payload: 10
request_memory: 512
servers:
- name: myapp-1
host: 192.168.1.1
web_server: true
- name: myapp-2
host: 192.168.1.2This defines a cluster of two servers, one with and one without a web server (Nginx & PHP-FPM).
The php & request_* attributes specify the PHP versions to be installed as well as the maximum duration, payload size, and memory that each HTTP request may consume.
This file functions similarly to a docker file for a cluster. It specifies the environment in which an app (or set of apps) will operate.
Next, I looked into defining the deployment plan for an application. I had this for a Laravel app:
repo: [email protected]:org/repo.git
php: 8.2
composer_command: install --prefer-dist --no-progress --no-interaction --no-dev --optimize-autoloader --quiet
release_commands:
- artisan config:cache
- artisan route:cache
- artisan event:cache
- artisan view:cache
cluster: staging
servers:
- name: myapp-1
- name: myapp-2
deploy_commands:
- artisan migrate --force
- artisan queue:restartTo achieve zero-downtime PHP deployments, we must point Nginx to a symlink directory (/current) and atomically switch the link to the most recent release while deploying. Requests that began on an earlier version of the application will continue to be processed on that version, while new requests will be processed on the new version.
With that, we ensure that no requests will fail due to executing files from two different versions of the application. Furthermore, new requests will not have to wait too long for the new version to be published because a symlink switch is so fast that it has almost no effect on latency.
To put this deployment strategy into action, we must ensure that certain files and directories are used by all versions.
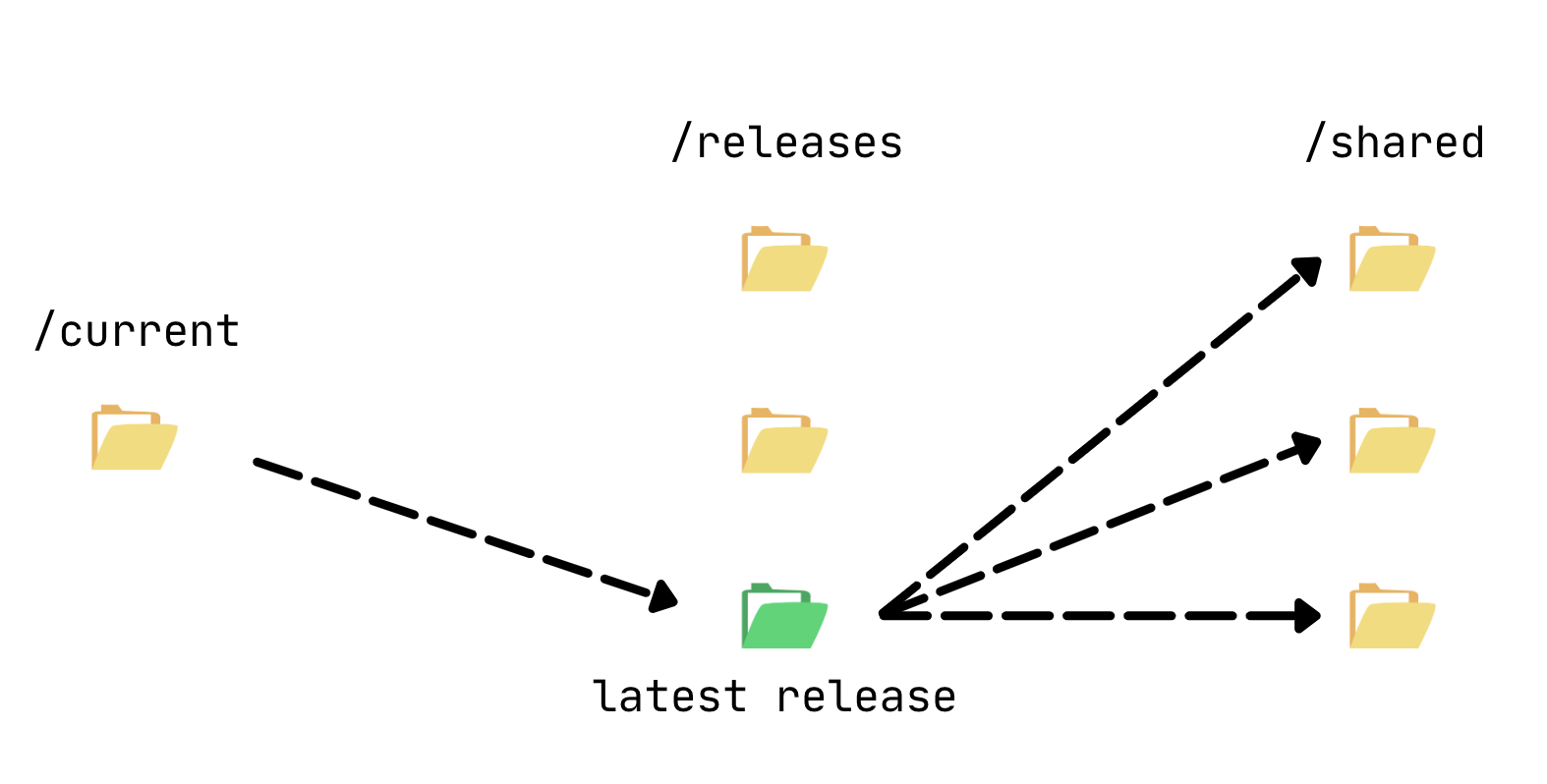
Because different files or directories may need to persist between deployments depending on the application, I added a new attribute to the app definition file:
linked_dirs:
- storage/app/public
- storage/framework/cache/data
- storage/framework/sessionsFor Nginx & PHP-FPM, we need to configure a few things on each server:
servers:
- name: myapp-1
web:
max_workers: 15
min_spare_workers: 5
initial_workers: 7
max_spare_workers: 10
- name: myapp-2
deploy_commands:
- artisan migrate --force
- artisan queue:restartIn this section, I state that FPM on myapp-1 should begin with 7 workers and can increase to 15 workers for this app. This allows 7 to 15 requests to be handled at the same time.
Then on the myapp-2 server, I configure the queue workers & scheduled jobs:
servers:
- name: myapp-1
web:
max_workers: 15
min_spare_workers: 5
initial_workers: 7
max_spare_workers: 10
- name: myapp-2
deploy_commands:
- artisan migrate --force
- artisan queue:restart
queues:
- name: default
command: queue:work default --sleep=1 --timeout=20
workers: 5
stop_wait_timeout: 3600
- name: reports
command: queue:work reports --sleep=1 --timeout=60
workers: 5
stop_wait_timeout: 3600
scheduler: onThis should result in 10 workers on this server, 5 for the default connection and 5 for the reports connection.
I should also have the schedule:run command invoked every minute to run any scheduled tasks.
My initial thought was to write several bash scripts that read the definition files and use the APIs of Forge and Envoyer to orchestrate everything.
I tried this approach for a few days before realizing two things:
- APIs were not designed for this type of automation. It takes several API calls to complete tasks, and I have to wait for background workers to finish one before starting another.
- A significant portion of the applications I manage fall into a category where following certain rules is critical. Access to the servers is governed by one of these rules. Access to production servers is basically restricted to specific personnel and servers within the same VPC.
It was time to call on my decade of bash scripting experience and start writing my own scripts. But wait, I've got GoLang in my toolbox. I can use it to construct the entire thing. I can even run things on multiple servers at the same time using goroutines.
GoLang generates a static binary. As a result, I can run the binary anywhere, just like a bash script, without having to set up an environment.
I can execute the binary from my machine for apps that must adhere to specific regulations, and I can execute it on GitHub actions for other apps (both business and personal).
After a few design iterations, I settled on a design that checked all of my boxes. I also decided on the name "Flight" for the tool, which was inspired by the title "Flight Director" in NASA missions.

To configure a server cluster, I created the following command:
flight provision <CLUSTER_NAME>This command creates an SSH pool that manages connections to various cluster servers and uses these connections to run various commands.
The following tasks must be completed on each server:
- Install required libraries (
supervisor,openssh-client,curl, etc...). - Ensure that Nginx is installed and configured on all servers with the
web_servertag. - Ensure that the various PHP versions, as well as common PHP extensions, are installed.
- Ensure that PHP-FPM is installed and configured on
web_serverservers. - Check that composer is installed.
This command only installs; it does not remove or upgrade. In other words, I can run it as many times as I want (to add new servers or update configurations) without fear of accidentally removing or upgrading any libraries.
I prefer to perform removals and upgrades manually, which I do no more than once or twice a year. That's an overhead I can manage.
With the servers ready to run the PHP applications, the next step is to upload the application version that needs to be deployed & prepare it for a potential release. This task is accomplished with this command:
flight app:release <APP_NAME> <COMMIT_SHA>This procedure begins by downloading the release files from GitHub. I tried a few approaches and settled on one in which Flight downloads a local mirror of the repository and uses it to archive a specific commit hash into a single tarball (.tar.gz).
With this approach, I only need to add a single deployment key to the app repository on GitHub. The same key will be used to create the build locally and upload it to all servers, regardless of how many servers I add to the cluster in the future.
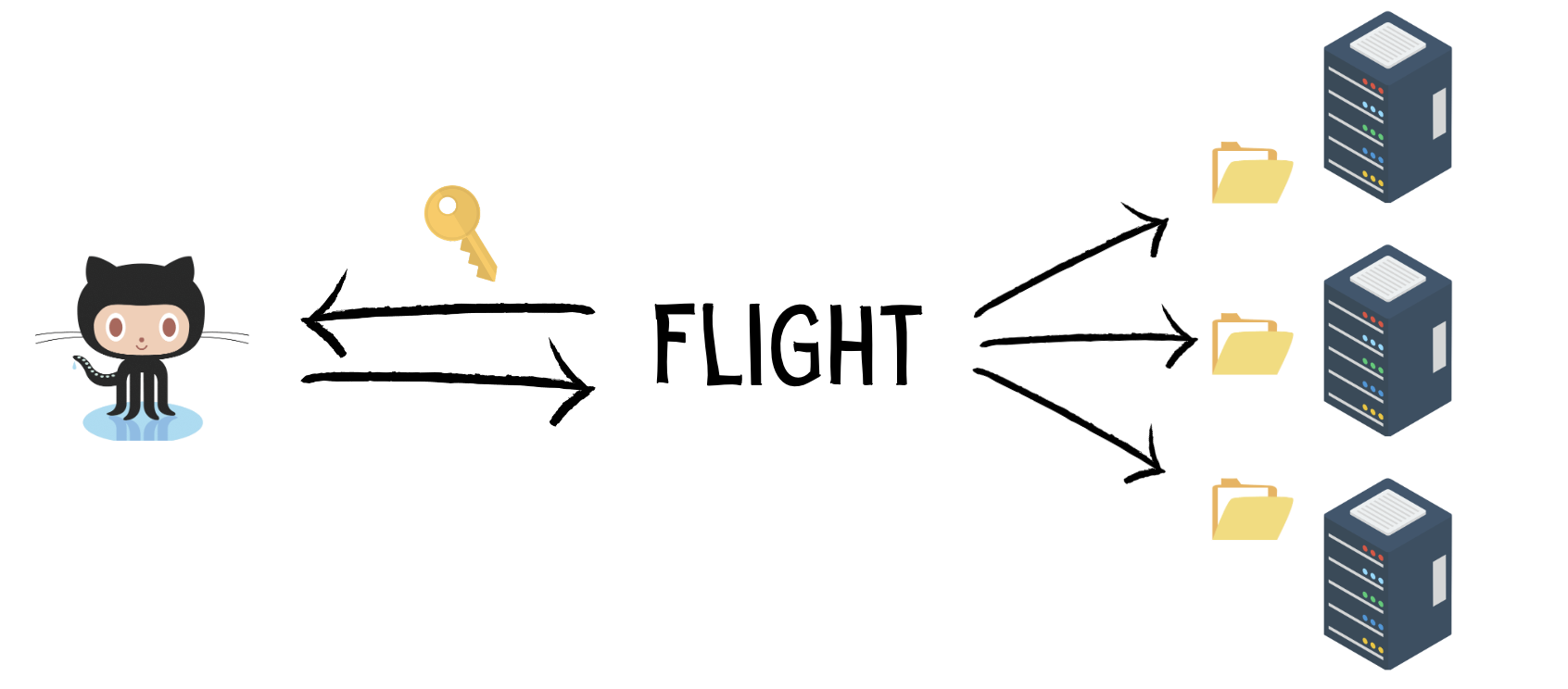
Now that the build is complete locally, Flight must upload it to each server and extract it into a release directory.
I chose to isolate each app under a separate system user for security reasons. As a result, a rogue script running in one app will not have access to files belonging to another app.
So, before uploading the build, Flight creates a system user for the app (if one does not already exist) on all servers, as well as a few directories under that user for organization.
After that, the build is uploaded to each server and extracted into a directory owned by the dedicated system user (for example, /home/myapp/myapp...).
Flight must now create a few symlinks for shared files and directories inside the ./flight/shared directory in order to perform zero-downtime deployments. These directories and files are created only once and symlinked to each release directory.
Flight then runs the composer command (composer install) and release commands in the release directory on all servers. Then it executes deployment commands specific to each server.
We now have a ready-to-go release, and the final step is to create a symlink between the release directory and a current directory.
When passing requests to PHP-FPM, Nginx uses this current to set the DOCUMENT_ROOT header to the real path of the release directory. This allows PHP to see only the release's real path, not the symlink.
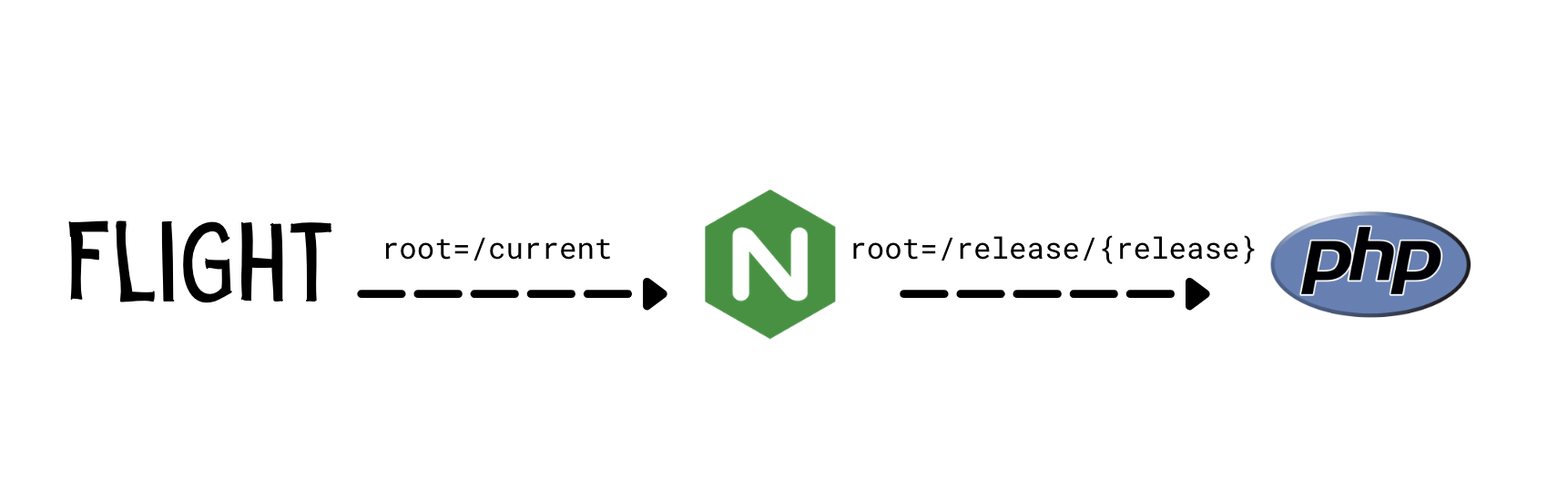
PHP-FPM will cache PHP scripts in the OPCache separately for each release as a result. This prevents a request from loading two different PHP files from two different releases in the middle of a deployment.
To avoid triggering a deployment every time I change some of the configuration attributes (which I dislike about docker deployments), I've separated the app configuration task into a separate command.
This is how it looks:
flight app:configure <APP_NAME>The app:configure command does three things:
- Configures FPM & Nginx to handle web requests.
- Configures queue workers.
- Configures the scheduler.
For FPM, Flight configures a pool of workers that are managed by the master FPM process. FPM then listens on a special Unix socket for requests to the app and routes them to available workers.
Controlling the pool on each server is done using the web attribute of the definition file:
web:
max_workers: 15
min_spare_workers: 5
initial_workers: 7
max_spare_workers: 10Flight configures Nginx to use APP_PATH/current/public as the root for requests to the app domain. It also sets the DOCUMENT_ROOT header to Nginx's variable $realpath_root. As previously explained, this causes PHP to read the application files from the release directory rather than the symlink.
This also makes us avoid reloading PHP-FPM to clear the cache between deployments, which forces the master process to hold all requests received over the Unix socket until all children have reloaded.
This usually does not result in downtime or errors, but it does add noticeable latency to incoming requests. This latency may cause downtime (requests failing before any worker can handle them) in a high traffic environment.
Flight reloads PHP-FPM and Nginx after they have been configured. That is another reason why configuration updates must be performed separately. This gives me control over when a reload occurs.
If I need to make non-urgent changes, I update the app definition file and schedule the app:configure command to run when there is little traffic. If a critical situation necessitates configuration updates, I make them right away. In any case, it's a critical situation, which means that some traffic is being dropped or has high latency.
Now, for queue configurations, Flight manages a supervisor configuration file on each server that runs workers. This file manages a number of workers and configures them to send their output to a log file in the release directory's /storage/log directory.
Because logs are kept in the release directory, each deployment gets a new file. This makes it simple to navigate the logs and associate them with specific releases.
The final step is to configure the scheduler. Flight uses crontab for that. It creates a configuration file that executes the schedule:run command every minute and logs the results in the /storage/log directory.
Laravel has a env:encrypt command for encrypting environment files and safely pushing them to git. After a deployment, you must run env:decrypt and provide the encryption key used to encrypt the file to update the file on the server.
I wanted more control over the process because some of the environmental secrets we manage are extremely sensitive, and accidentally leaking them would necessitate a lengthy process of acquiring new ones.
So I've added the commands env:pull and env:push to Flight. The former downloads the environment file for a specific app from the first server to my local machine. I then make the desired changes and use env:push to upload the file to all servers via SSH and update the cached configurations.
This allows me to change environment variables without triggering a full deployment. Furthermore, only authorized personnel with access to the app definition file and private keys with access to the servers can pull and inspect the file.
I currently have two GitHub repositories: one with definition files for clusters and apps belonging to my organization, and one for personal use.
I manage the infrastructure and deployments for personal applications from my local machine. I update the definition files, then run the provision, app:configure, and app:release Flight commands, and that's it.
For organization applications, I built a tiny server within the same VPC as the production servers. This server contains all of the private keys required to connect to the various clusters via SSH.
This server is only accessible to a few key people. We have a firewall in place that prevents access to the SSH port (custom port) unless it comes from specific IP addresses.
On this server, I installed the Flight binary and retrieved the git repository containing the definition files. Flight commands are only executed on this server.
The issue with this approach is that each time a team needs to push a release, I have to SSH into the server and trigger deployments. Given the number of teams and applications, this isn't ideal.
As a result, I added a serve command to Flight. This command launches a web server on a specific port and listens for deployment requests. Once all tests have passed, I use 'curl' inside the GitHub action that runs the tests before a deployment to ping the deployment server. The ping contains an app token as well as the commit SHA.
When the server receives an app deployment request, it initiates the release process in the same way that the flight app:release command does. This gives me the flexibility to trigger deployments from the terminal when I need, and also handle deployment requests coming from GitHub actions automatically.
Deployments occur far more frequently than cluster or application configuration updates. With that deployment web server, I rarely have to manually trigger deployments anymore. This allows me to focus on other aspects of the infrastructure.
When it comes to the symlink deployment strategy, there are a few things to consider about OPcache.
First, PHP will not find a cache entry for any PHP scripts (application or vendor scripts) in the new release, which means it will have to recompile everything once requests start coming in.
Under high traffic, this causes a CPU spike because each FPM worker handling a request compiles all scripts required by the request. The "thundering herd problem" describes this situation.
To reduce the likelihood of this happening, we are currently avoiding deploying during peak traffic times unless absolutely necessary.
Second, as new releases are deployed, the OPcache is filled with new cached PHP scripts while the old scripts are not cleared. As a result, available memory is used inefficiently.
OPcache restarts when the memory is full. This results in the thundering herd problem described in the previous section.
To address this issue, we reload php-fpm on a regular basis during low-traffic times. As previously stated, this adds some latency but prevents OPCache from restarting in the middle of peak traffic times.
This solution appears to be functional. However, to compensate for the wasted memory, we must run our machines with more memory than the application requires.
I'm keeping an eye on things and intend to experiment with a alternating directory strategy in which releases are placed in either directory A or B. The symlink is then directed to the directory containing the most recent release.
With this strategy, files that weren't modified between every other release are kept in the same directory, which means OPcache will only have two versions of every file rather than multiple versions (one for each release). It also means these files won't trigger a re-compile since they are present in the cache.
For this to work, I have to enable OPcache's automatic invalidation based on files timestamp:
opcache.validate_timestamps=1
opcache.revalidate_freq=0This causes PHP to check the timestamp of each file on every request and recompile if the timestamp has changed since the last compile. Otherwise, the cache will be reused.
However, I'm not sure about the overhead of checking the timestamp on each request. If I increase the frequency, incoming requests may reach the server before the cache is invalidated, resulting in the serving of old cached scripts rather than new ones. I'll have to put it to the test.
Another issue with this strategy is that git does not maintain file timestamps, so files will have a new timestamp with each new release. This is probably fine because the large bulk is usually inside the vendor directory, which git will not handle.
What I'd like to add next is the ability to dynamically add and remove servers from a cluster. This will enable us to implement autoscaling into our infrastructure, in which new servers are added or removed based on traffic volume.
Flight's web server would handle this. Flight receives a ping to provision and prepare the release of a new server before it goes live. When the server is removed from the load balancer, it receives another ping and stops sending new releases to it.
Another possibility is to communicate a high rate of 500 errors between our monitoring service and Flight. If a recent release was deployed, Flight would automatically rollback because it was most likely faulty.
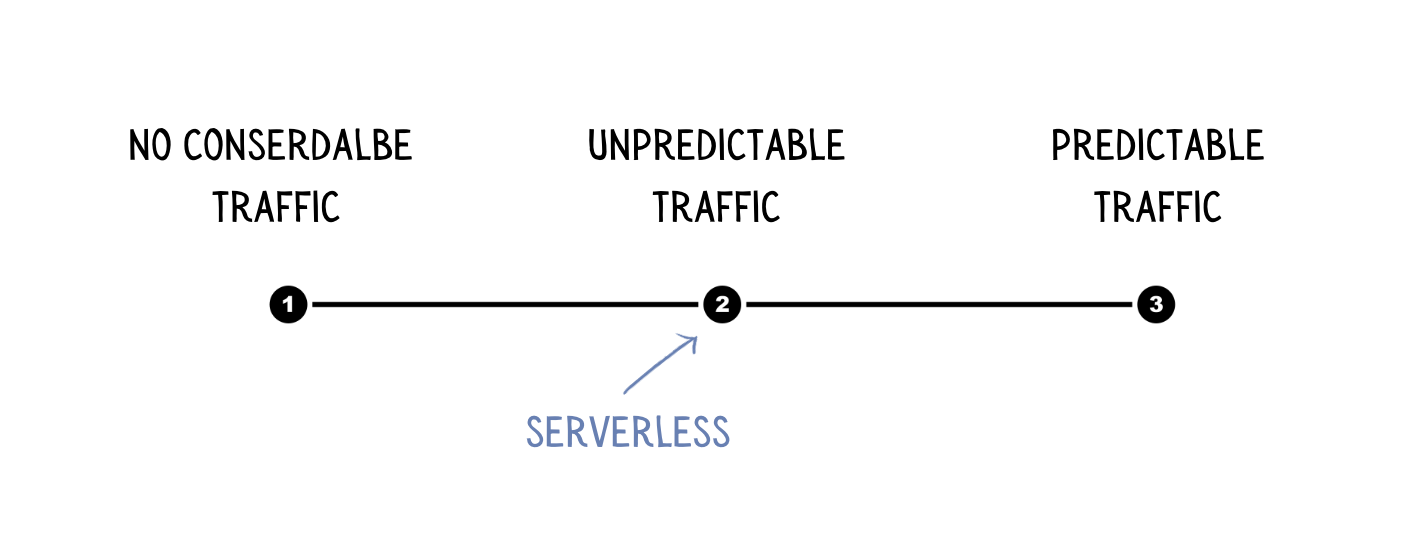
That was a question raised by several team members. Why go back to servers after running serverless for a few years?
Consider a comparison of short-term Airbnb rentals and long-term rentals to understand why. Short-term rentals charge a premium for the ability to move at any time. You don't know where you want to stay yet, so you're bouncing around until you do.
When you've figured it out, you sign a long-term contract. Which is less expensive and gives you more freedom to organize the space as you see fit.
Now, serverless is ideal for situations where flexibility is required. You don't know how much compute power you'll need or what the traffic patterns will be. So you pay a premium to scale without being concerned.
When your needs are quantifiable, paying the premium no longer makes sense. Especially in a high traffic environment where the premium is significant.
Cold starts are another major issue with serverless. The provider may decide to kill specific hosts and move our serverless containers to another at any time. When this happens, new requests hit a cold start, which increases the latency.
We've seen this happen several times, and it's especially aggravating when it happens during peak traffic hours.
Even if this is not the case, a burst of traffic will experience a cold start if all available serverless containers are serving other traffic. To address this, most platforms allow you to keep a set number of containers warm by sending a warmer ping every 5 minutes.
The issue is that during peak traffic, warmer pings compete for available containers with actual requests. Because available containers are handling warmer pings, some requests may experience a cold start.
Given the two concerns I raised above, I believe that serverless is ideal for the period between "no significant traffic yet" and "traffic is steady and predictable." Servers rule before and after that point on your timeline.
Every requirement is unique; there is no one-size-fits-all solution. Infrastructure as code (IaC) proved to be an efficient strategy for managing and provisioning infrastructure under my supervision for my specific needs. I use CloudFormation and Flight to manage a large number of servers and applications while adhering to certain compliance rules.
Check to see if your needs align with the strategy you're interested in before changing how you manage your infrastructure. In this article, I attempted to explain my needs and motivations as best I could.